
Computer Architecture (Professor Weiwu Hu): Key Concepts and Notes
计算机体系结构
静态流水线
一、指令流水线的相关:
- 数据相关:多个指令使用同一个寄存器
- 假相关:WAW、WAR(乱序执行才会出现,可以彻底解决)
- 真相关:RAW(通过前递、静态调度解决)
- 控制相关:与 PC 有关
- 转移指令(通过把地址计算提前到译码级、增加转移延迟槽解决)
- 结构相关:资源冲突
- IF 和 MEM 都需要访问存储器
二、精确例外:把每条指令的例外延迟到 WB 时再处理
- 对机器状态的修改也在 WB 阶段进行
- 对状态寄存器的修改从 EX 阶段延迟到 WB 阶段
- 指定一个通用寄存器中(如最后一个)为例外处理时保存 PC 值专用
三、多功能部件及多拍操作流水线:
- 通过流水线堵塞来保证避免数据冲突:比较寄存器号
- 结构相关:通过请求和仲裁允许流水线前进
- 例外处理:所有指令顺序写回,而且所有例外在写回阶段进行统一处理
动态流水线
一、不同方法:
| 技术 | 作用 |
|---|---|
| 寄存器重命名 | 解决 WAW、WAR 相关 |
| 循环展开 & 转移猜测 | 解决转移指令引起的控制相关 |
| 简单流水线 & 计分板动态调度 | 解决 RAW 相关 |
程序的相关性(注意和指令的相关性区分开来):
- 数据相关(真相关):RAW
- 名字相关:
- WAW:输出相关
- WAR:逆相关
- 控制相关:条件转移
二、静态(软件)调度:
- 编译器的静态调度(一般来说,三者会一起用)
- 循环展开:相关指令隔得足够开,用其他指令填充(注意利用转移延迟槽)
- 软件重命名寄存器
- 重排:变换次序
三、动态(硬件)调度:
-
把译码分成两个阶段:发射和读操作数
-
寄存器重命名:通过标志,解决 WAW 和 WAR
- 哪个号作为重命名号,那么这个号的顺序是给定的,其他号的顺序是基于这个号的
四、Tomasulo 算法:
- 结构:
- 保留站(保留站号作为重命名号,发挥重命名寄存器的作用):记录某一个指令的源操作数是否准备好
- 寄存器堆:存在一个域,记录产生结果的保留站号(保留站前读寄存器的缺点)
- 步骤:
- 发射
- 执行
- 写回(写回需要写回寄存器,以及通知保留站中,等待对应寄存器结果的源操作数)
五、动态流水线的例外处理:
- 思想:
- 写回时不直接写到寄存器或存储器,而是写到缓冲器中
- 有序发射、乱序执行、有序提交
- 保留站把有序变成乱序,ROB 把乱序变成有序
- 结构:
- 保留站
- 寄存器堆
- ROB(ROB 号作为重命名号)
- 步骤:
- 发射
- 执行
- 写回(写回需要写回 ROB,以及通知保留站中,等待对应寄存器结果的源操作数)
- 提交
- 假设某个指令发生了溢出例外:延迟到提交才处理(目的是将后面指令对于机器状态的修改,延迟到前面指令都执行完毕),刷空 ROB、保留站
总结:
- 保留站:暂存指令
- 重命名寄存器:暂存数据
- 步骤:
- 发射(分配重命名寄存器-读寄存器-写保留站)
- 执行(运算 OR 侦听等待):若操作数准备好,则执行;否则侦听结果总线
- 写回(写结果总线):写结果总线,通知 ROB 项和保留站对应项,释放保留站
- 提交(写结构寄存器-释放重命名寄存器)
多发射
一、提高指令并行度的关键技术:
- 流水线
- 多发射
- 乱序执行
- 动态调度:有序进入、乱序执行、有序结束
- 转移猜测
- 非阻塞缓存
- 喂饱“饥饿”的运算器
- 转移猜测:提供足够的指令
- 存储管理:提供足够的数据
- 冯诺依曼结构:存储程序和顺序执行
二、影响动态调度的主要因素:
- 指令缓存的结构(保留站的组织)
- 独立
- 分组
- 全局
- 读寄存器内容的时机(保留站和寄存器的关系)
- 保留站前读寄存器(译码时读寄存器)
- 保留站后读寄存器(发射时读寄存器)(主流)
- 保留站中无值域,较简单
- 保留站确信所有值都已经准备好后再读寄存器,有可能有 Forward 的情况
- 操作数全部准备好后才能读寄存器
- 乱序发射
- 可以减少一次源操作数拷贝:从寄存器到保留站
- 寄存器重命名方法
- 重命名寄存器和结构寄存器分开(独立重命名寄存器):重命名到保留站、ROB、发射队列
- 重命名寄存器的状态:EMPTY、MAPPED、WRITEBACK
- 结构寄存器的状态:VALID、INVALID
- 重命名寄存器和结构寄存器不分开(物理寄存器堆):建立和维护逻辑寄存器和物理寄存器之间的映射表(重命名表)
- 映射表的组织形式:RAM(倒排,项数等于逻辑寄存器数)、CAM(项数等于物理寄存器数)
- 映射表的域:name、valid、state(EMPTY、MAPPED、WRITEBACK、COMMIT)
- 可以减少一次结果操作数拷贝:从物理寄存器到结构寄存器
- 重命名寄存器和结构寄存器分开(独立重命名寄存器):重命名到保留站、ROB、发射队列
(不同于 Tomasulo 算法所划分的流水级,缺失了写回级,同时对发射的定义不同)
三、重命名算法(保留站前读寄存器):
- 译码(分配重命名寄存器-读寄存器-写保留站):为目标寄存器分配重命名寄存器;为源寄存器找到对应的重命名或结构寄存器;读操作数并送入保留站
- 发射(从保留站中发射指令):在保留站中找操作数准备好的操作进行运算
- 执行(写结果总线):执行结果写结果总线,写回重命名寄存器;写回对应的保留站
- 提交(写结构寄存器-释放重命名寄存器):将重命名寄存器的结果写回结构寄存器;释放对应的重命名寄存器
四、重命名算法(保留站后读寄存器):
- 译码(分配重命名寄存器-写保留站):此时分配重命名寄存器,即找到空闲的物理寄存器
- 发射(从保留站中发射指令-读寄存器):考虑 Forwarding,从物理寄存器或结果总线中读寄存器的值
- 执行(写结果总线):写回物理寄存器;不写回保留站
- 提交(修改重命名表-释放重命名寄存器)
龙芯 2 号的流水线:取指、预译码、译码、寄存器重命名、调度(写保留站)、发射、读寄存器、执行、提交
五、多发射:
- 数据通路变宽:
- 寄存器读端口变多
- 访存端口要求也增加
- 不同阶段的宽度可能不同,一般来说四发射指的是最窄的宽度是四
- 流水线复杂度与发射宽度成平方关系
- 如发射队列(保留站)变大*(读端口变多+侦听端口变多)
- 如寄存器重命名端口变多*同一拍重命名指令相关
- 重命名逻辑随发射宽度的平方复杂度(相当于一个$O(n^2)$问题,涉及到如何在一个表中高效找到若干个空位置)
- 设计问题:
- 同时提交多条指令:前后看、左右看
- 指令发射和读寄存器:多端口寄存器;指令发射应该考虑让前面的指令先发射
- 多功能部件
转移猜测
一、转移指令
多发射情况下延迟槽成为需要专门照顾的负担
类型(属性):
- 条件转移与非条件转移
- 直接转移与间接转移
- 相对转移与绝对转移
二、程序的转移行为
- 分支指令是很频繁的
- 分支指令有较好的局部性
- 分支指令具有可预测性
三、软件方法解决控制相关
解决转移条件相关的方法:
-
阻塞
- 用延迟槽容忍延迟
- 超流水情况下一条延迟槽不够
- 多发射情况下延迟槽反而成为需要特殊照顾的兼容负担
- 编译器优化:
- 循环展开:循环展开+软件寄存器重命名+变换次序(缺点:不好展开、寄存器不够、增加指令 cache 负担)
- 软流水:新循环体的每个操作来自不同的循环体,以分开数据相关的指令,相当于软件的 Tomasulo 算法,是符号级的循环展开
- 全局代码调度
- 转换为数据相关
- 把条件转移指令转换为条件执行
- 硬件转移预测
- 在取指或译码阶段预测转移是否成功和转移目标
- 在执行阶段判断转移预测是否正确
四、硬件动态转移预测
原理:根据过去记录和当前指令信息,预测转移方向和目标地址
类型:静态(恒定预测)、动态(根据历史预测)、混合(结合静态和动态)
转移历史表(Branch History Table,BHT 表,历史表):
- 利用单个分支的重复性
- BHR(Branch History Register):程序中所有转移指令过去 m 次的转移记录
- PC 低 k 位索引,每一 BHT 表项 1 位 / 2 位(饱和计数,10 和 11 为 taken)
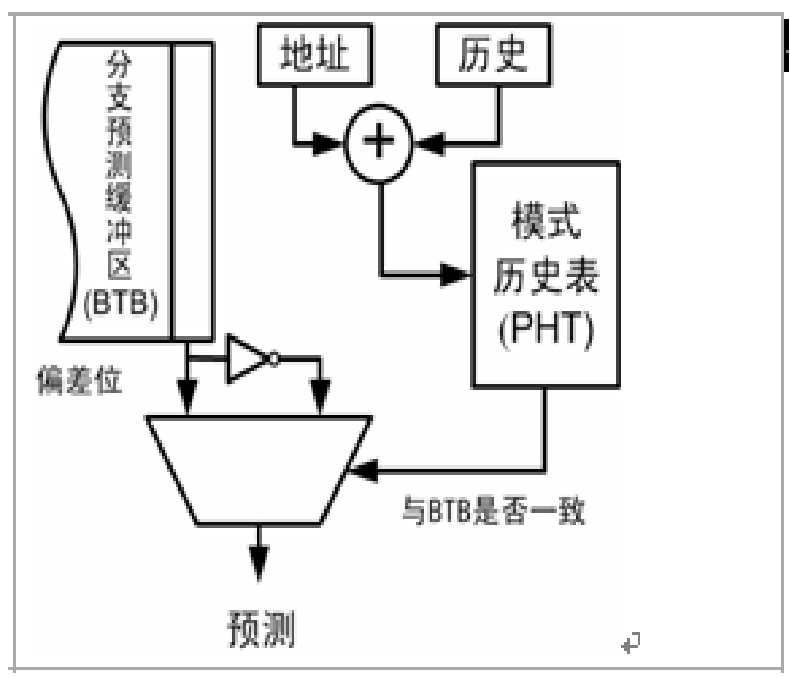
转移目标缓冲器(Branch Target Buffer,BTB 表):
- 减少猜测延迟
- 因为间接跳转指令的跳转地址不能从指令中获得,因此需要 BTB 表预测转移地址
- BTB 使用 CAM 结构,根据当前完整的 PC 值进行全相等比较,找到表项,预测转移方向(BHT)和转移地址
- 失效时进行替换
返回地址栈:
- 函数调用时压栈,返回时从栈顶弹出作为返回地址
转移模式历史表(Pattern History Table,PHT 表,模式表):
- 某个转移指令过去 m 次转移记录
- BHR 和 PHT 的组织方式(先索引出 BHR / GHR,再索引 PHT):
- GAg:Global Address BHR, index to PHT
- PAp:Per Address BHR with full PC, index to PHT
- SAs:Set Address BHR with partial PC, index to PHT
分支别名干扰(不同分支指令使用同一个 PHT,并且不同的分支指令很大概率发生分支冲突)的消除:
- 解决办法:
- 增大预测器(增大表)
- 更高效的索引方式:Gshare
- 分离不同类型的分支,使用不同的预测方案
- 将负面干扰转换为其他干扰
- Gselect:全局历史 m 位和地址 n 位组合,索引 PHT 表
- Gshare:部分地址和全局历史异或,索引 PHT 表
- Agree分支预测:
- 在指令 cache 或 BTB 中设置偏向位,保存的是这条指令最常见的转移方向
- PHT 的 2 位计数不是预测转移方向,而是决定是否按照偏向位转移,如果转移方向和偏向位一致,饱和计数增加
- 例子:假设 2 条转移指令使用同一项 PHT,预测成功的准确率分别为 85% 和 15%(也就是说,PHT 预测为 taken,但指令 A 85% 为 taken,而指令 B 15% 为 taken),
- 使用普通的 PHT 表:如果两条指令实际的跳转方向是相同的,就不会引起分支别名干扰,这时候共享同一个 PHT 是没问题的,但如果两条指令实际的跳转方向是不同的,就会造成分支冲突,即 \(0.85*0.85 + 0.15*0.15\)
- 使用 Agree:意味着两条指令各有 85% 同意偏向位(指令 A 的偏向位为 taken,指令 B 的偏向位为 nottaken,而此时 PHT 表项原含义为 taken,现含义为同意偏向位,意味着指令 A 一直预测 taken,指令 B 一直预测 nottaken),那么分支冲突的概率为\(0.85*0.15+0.15*0.85\)
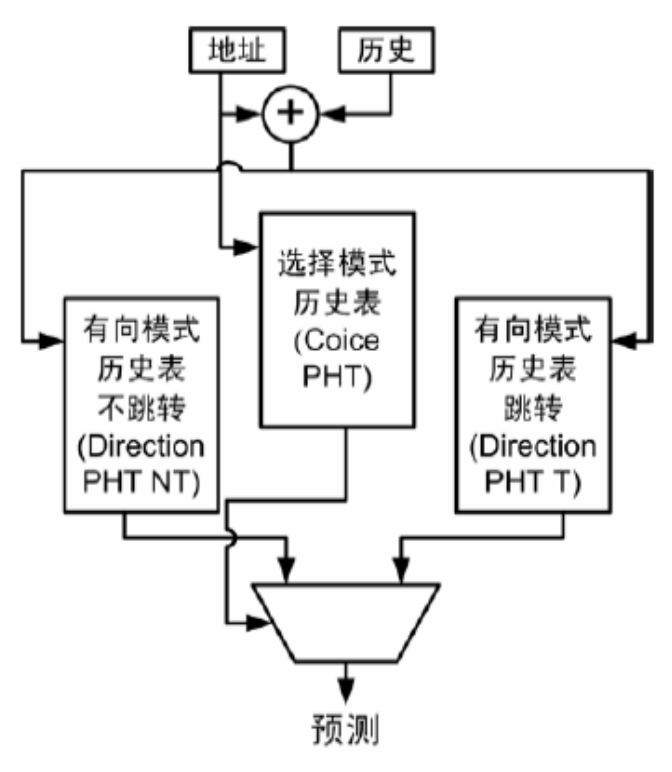
- Bi-Mode 预测器:
小结(不要太过关注具体办法,而是抓住问题):
- 分支指令对性能影响非常大;分支指令具有可预测性$\Rightarrow$要做好的预测器
- 好的预测器$\Rightarrow$预测精度要高;预测正确所付出的代价要低;预测错误所付出的代价要低
- 要实现好的转移预测器$\Rightarrow$提高准确度;预测错误后保证现场准确性、识别需要取消的指令
- 转移指令具有重复性和偏向性$\Rightarrow$BHT 表
- 转移指令具有相关性$\Rightarrow$BHT+PHT 两层预测器
- 转移预测存在分支别名干扰问题$\Rightarrow$Gshare、Agree 等
- 没有万能的转移预测$\Rightarrow$混合预测器
五、常见处理器的转移猜测
运算部件
一、定点补码加法器设计
- 全加器
- 串行进位加法器
- 先行进位加法器
- 块内并行,块间串行
- 块内并行,块间并行:定义块间的生成因子和传递因子
- 用加法做减法
- 溢出判断:取加数的符号位和结果的符号位进行与或判断
二、定点 ALU 设计
- 判断相等
- 判断大小
- 移位
三、定点补码乘法器设计
- 原理:\([X*Y]_{补}=[X]_{补}*Y\)
- 32 位无符号定点补码乘法
- 通过 Booth 二位一乘,变成 16 个 64 位部分积相加
- 通过 64 个 16 个数相加的 1-bit 华莱士树,变成 2 个 64 位数相加
- 华莱士树需要注意的地方:
- 不能从同一层拿进位输出,进位必须往上走
- 华莱士树中存在一个半加器,Booth 二位一乘涉及的取反加一的一,可以留到华莱士树的进位输入中
高速缓存
一、存储层次
摩尔定律使 CPU 的内容发生了变化:从运算器+控制器,增加了部分存储器
二、cache 结构
cache 块的位置(内存和 cache 映射关系):
- 全相联
- 内存单位映射到所有 cache 块
- 命中率高、硬件复杂、延迟大、需要对所有 cache 块并行比较
- 组相联
- 内存单位映射到一组 cache 块
- 直接相联
- 内存单位映射到唯一 cache 块
- 命中率低、硬件简单、延迟最小
cache 替换机制:
- 随机、LRU、FIFO
写策略:
- 写命中:
- write back:只写 cache 不写内存
- write through:写 cache 的同时写内存
- 写失效:
- write allocate(搭配写回):把块读到 cache,再在 cache 写
- write non-allocate(搭配写穿透):直接写进内存
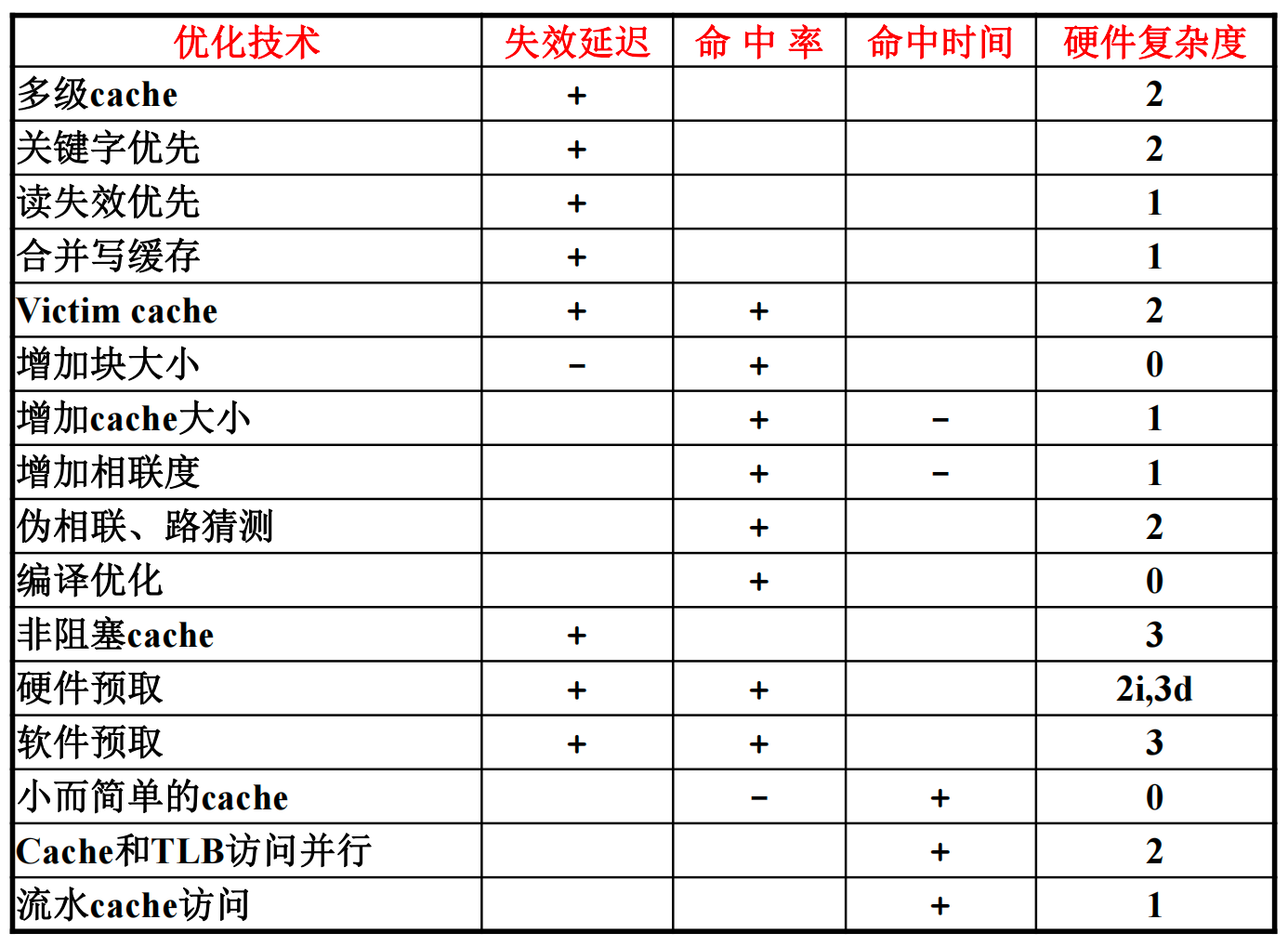
三、cache 性能优化
AMAT(Average Memory Access Time)= HitTime + MissRate * MissPenalty
失效的因素:
- 冷失效(Cold Miss、Compulsory Miss)
- 容量失效(Capacity Miss)
- 冲突失效(Conflict Miss)
- 不同 cache 块的 index 相同
- 全相联不存在,退化成容量失效
- 一致性失效(Coherence Miss)
降低失效率 MissRate:
- 增加块大小
- 增加 cache 容量
- 一级 cache 访问直接决定时钟周期
- 增大片内 cache 大小,增加芯片面积
- 增加相联数量
- 2:1 规则
- 但是会增加时钟延迟,而且 cache 访问路径可能是整个处理器的关键路径
- 路预测
- 结合直接相联延迟低、组相联命中率高的优点,同时还能降低功耗
- 每次 cache 访问只检查一路,如果不命中再检查其他路
- 软件优化:增加空间局部性
- 数组合并
- 循环交换
- 循环合并
- 数组分块
降低失效延迟 MissPenalty(通常需要从整个流水线的角度考虑):
- 关键字优先:优先访问读访问需要的字
- 读失效优先:
- 读 cache 失效对流水线效率的影响比写 cache 失效要大:一般有写缓存 Write Buffer,写指令只需要把数据写到写缓存就能提交,再由写缓存写到 cache 或内存;而取数指令必须等到数据取回来才能提交,也因此造成后面相关指令的堵塞
- 优先处理读失效
- Victim cache:
- 指的是用来保存从 cache 中替换出来数据的 cache
- 在直接相联的 cache 中避免冲突失效
- 写合并
- 设置写缓存
- 在写缓存中,把对同一 cache 块的写操作进行合并(IO 操作不可以合并)
- 多级 cache
降低命中延迟 HitTime:
- 简化 cache 设计
- cache 越小,延迟越小
- 相联数越小,延迟越小
- 需要统筹考虑,简化一级 cache 设计(有时候需要用失效率换失效延迟)
- 避免地址转换延迟:虚地址 cache
- 虚地址直接访问 cache,减少了虚实地址转换的时间
- 进程切换时会刷 cache 以维护一致性,但增加了冷失效:在 TLB 中增加进程号解决
- 虚 Index 实 Tag 技术:
- 在用 index 从 cache 中读 tag 的同时,进行虚实地址转换,可以使用物理地址做 tag
- 如何保证虚实地址 index 位一致:
- 增加页大小、增加相联度,杜绝冲突地址段
- 软件保证:页着色(解决 cache 别名问题),保证 cache 内一一对应(虚地址与实地址一一对应)
- 为什么会有 cache 别名问题:存在多个虚地址对应同一个实地址的情况,而由于虚地址的 index 不同导致在 cache 中存在多个备份的情况
- 操作系统层面的页着色是如何解决的:在页分配的时候,保证虚页和实页的颜色一样,即对于 cache 的索引最高位超过了页内地址的最高位时,保证在冲突地址段内,一个虚地址只会对应一个实地址,进而保证虚实地址 index 位一致
- 并行访问 cache 和 TLB
- 增加 cache 访问流水级
- cache 访问时间是处理器主频的决定因素之一
- 把 cache 访问分成多拍提高主频,但是增加了 load-to-use
提高 cache 访问的并行性(主要是降低失效延迟)
- 多访存部件:提高访存的吞吐率
- 非阻塞 cache:
- cache 在访问失效时允许后续的访问继续进行
- 需要类似保留站的访存队列机制
- 硬件预取:
- 指令预取:在 cache 失效时取连续两块
- 数据预取
- 现代处理器都实现复杂预取技术
- 软件预取:
- 都是数据预取
总结:
四、常见处理器的存储层次
存储管理
一、虚拟存储的基本原理
虚存:虚地址空间映射到物理内存,物理内存作为磁盘的 cache
多级页表:上一级页表存储的是下一级页表的 base
TLB:
- 页表的 cache
- 一般与 cache 的访问同时进行
cache 和虚存:
- cache 命中延迟 1-3 拍;虚存的命中延迟(内存命中) 50-150 拍
- cache 失效延迟 8-150 拍;虚存的失效延迟 10^6 - 10^7 拍,数量级相差巨大
- cache 中,通过硬件,实现物理地址到 cache 地址的映射(实地址 cache);虚存中,通过硬件(TLB)和操作系统,实现虚地址到实地址的映射
二、MIPS 对虚存系统的支持
MIPS 存储空间分段:
- kseg2/3、kseg1、kseg0、kuseg
- 其中 kseg1 和 kseg0 映射到相同的物理地址,都不能用 TLB,原因:
- IO 设备需要映射到 0-512MB 空间中,因此不能走 TLB
- kseg1 不能用 TLB,不能进 cache,原因:
- 在初始化时,CPU 刚通电,cache 和 TLB 还没有被初始化,用于初始化的指令不能进 cache,也不能用 TLB,这时候指令执行一般需要上百拍,很慢。等到 cache 和 TLB 被初始化后,转 kseg0 区,可以进 cache,速度就快很多了
- 关键就是:CPU 第一条指令必须是一个固定的入口,这个地址不能走 TLB,也不能用 cache
MIPS 的 TLB:
- 一个项管两页,也就是把连续两个虚页转换成两个实页
- 全相联
- 与 TLB 管理有关的指令:
- MFC0、MTC0:通用寄存器和控制寄存器之间搬运数据
- TLBR:读 TLB
- TLBWR、TLBWI:以 random 或 index 为索引,写 TLB
- 例外:
- 置 BadVaddr、Context(指向页表中相应项)、EntryHi
- 置 PC 为例外入口地址
- 置 status、cause
TLB 例外类型:
- TLB refill:不命中
- 读 Context
- 根据 Context 的地址,读取连续两个页表项
- 置 EntryLo0、EntryLo1
- TLBWR
- TLB invalid:命中,但无效,内存中没有该页
- TLB modify:命中,但已脏
Linux/MIPS 内存中的两级页表组织:
- 两级页表,每项 4 个字节
- 页表放在 kseg0,页表不引起 TLB 例外,页表存储空间在使用到的时候再分配
- 页表的基地址放在进程上下文中
例子:声明了一个16k 的 int 数组(64KB 地址空间),遍历赋值一次
(声明后,分配了虚拟地址空间,分配了页表,但页表还没初始化)
题目 1:页大小为 4KB,发生多少次例外?
解答 1:该数组占 16 页,考虑最理想情况(数组起始地址为页的起始地址等),发生 8 次 TLB refill,16 次 TLB invalid
题目 2:页大小为 4KB,上述程序执行完后发生进程切换,再执行遍历赋值
解答 2:
- TLB 被替换,但虚页还在内存中,只发生 8 次 TLB refill
- 数组被替换出内存,发生 8 次 TLB refill,16 次 TLB invalid
- 页表也被替换出内存呢?TLB refill 例外处理过程中,会发生 page miss,但这个分配页表的过程中不知道会不会把页表项装载进 TLB,否则会发生两次 TLB refill
三、LoogArch 对虚存系统的支持
四、TLB 的性能分析与优化
- 防缓冲区溢出攻击优化(利用缓冲区溢出,读取核心态的数据和代码):TLB 增加可执行位
- 性能优化方法(因为 TLB 也是 cache,所以和 cache 的优化方法是相同的):
- 增加 TLB 覆盖空间大小,降低 TLB miss 概率
- 增加页大小
- 降低 TLB 失效的开销
- 软 TLB:通过减少 TLB refill 处理过程 cache miss 的次数,减少处理过程的时间
- 增加 TLB 覆盖空间大小,降低 TLB miss 概率
多处理器
一、消息传递与共享存储
- 通用多核处理器一般采用共享存储结构
- 多个处理器核发出的访存指令次序如何约定?
- 存储一致性模型
- 多个处理器核间共享片上Cache如何组织及维护一致性?
- cache 一致性协议
二、共享存储系统中访存相关性
保证程序执行的一致性:
- 存储一致性模型和 cache 一致性协议
三、共享存储系统中访存事件次序
四、存储一致性模型(逐渐变弱)
- 顺序一致性:符合程序员直觉
- 处理机一致性:比顺序一致性弱
- 允许 store 之后的 load 越过 store 执行
- 实际上是把 write buffer 变得让用户可见:在使用 write buffer 时,store 提交后,即使还没有写到 cache 或内存中,后面的 load 就能从 write buffer 中取回数据,此时收到对 load 访问 cache 行的一个无效请求
- 弱一致性:把同步操作和普通访存操作区分开来,只在同步点维护一致性
- 所有同步操作完成后,才能做访存操作
- 所有访存操作完成后,才能做同步操作
- 释放一致性:对弱一致性模型的改进,把同步操作进一步分成获取操作 ACQUIRE 和释放操作 RELEASE
- 域一致性:对访存事件次序的要求不那么严格
- 冲突访问必须用同一把锁保护
- 单项一致性:必须为每一个共享变量指定相应的锁
- 加重了程序员负担
- 有利于提高性能
五、cache 一致性协议(与存储一致性模型是正交的,是为了实现某种存储一致性模型)
- 如何传播新值:写使无效 & 写更新
- write-invalidate:一个处理机更新某单位时,使得其他共享单元备份无效,其他处理机想要访问时再取得最新备份
- 优点:独占
- 缺点:假共享导致乒乓问题
- write-update:一个处理机更新某单位时,更新其他处理机的共享单元
- 优点:一直保持最新备份
- 缺点:即使其他处理机不再使用该共享单元,也每次更新
- write-invalidate:一个处理机更新某单位时,使得其他共享单元备份无效,其他处理机想要访问时再取得最新备份
- 谁可以产生新值:单写 & 多写
- 单写:任一时刻只有一个处理机能够写某个共享单位
- 多写:多个处理机能够同时写某个共享单位的不同部分
- 什么时候传播新值:急切更新 & 懒惰更新
- 普通 RC:写的同时,传输写操作
- Eager RC:把写操作延迟到 release 时再传输
- Lazy RC:在 Eager RC 的基础上,进一步延迟到下一次 acquire 时再传输
- 新值将会传播给谁:侦听协议 & 目录协议
- 侦听协议:通过广播维护一致性,广播新的值或所需的存储行地址
- 优点:利用总线,方便而快捷
- 缺点:可伸缩性有限,总线是独占资源
- 基于目录的协议:每个存储行对应一个目录项,记录 cache 出现在哪些核
- 优点:可伸缩性好
- 缺点:目录需要大量的存储空间,需要动态维护
- ESI 协议的 cache 状态:E、S、I
- 侦听协议:通过广播维护一致性,广播新的值或所需的存储行地址
书上例子:基于目录的、单写、写无效的 cache 一致性协议
- 处理机 i store x:
- 找到 x 的目录项,发送写请求
- 如果 x 是 clean(dirty),那么向包含 x 的处理机(独占的处理机)发送 invalid
- 包含 x 的处理机返回 invalid ack
- 向处理机 i 发送写同意
- 处理机 i load x:
- 找到 x 的目录项,发送读请求
- 如果 x 是 dirty,那么向包含 x 的独占处理机发送写请求(如果 x 是 clean,则直接发送读同意)
- 目标处理机更新 x 的目录项
- 向处理机 i 发送读同意